
Server Farm in the Palm of your hand |
I have recently been exploring Docker containers on SBCs (Small Board Computers), including the Raspberry Pi. The Docker eco-system is impressive in the amount of preconfigured containers that are available. However, as I have written before, it falls down on networking support, specifically the bolted-on-after-thought IPv6. The best one can do is NAT66 on IPv6, which just perpetuates the complexities (and evils) of NAT.
The biggest problem with the Docker IPv6 implementation is that it was an after thought. Unfortunately, this is not uncommon. Think of adding security after the fact, and you will quickly discover the poorly implemented security model. Docker is limited in this kind of after-thought thinking.
Linux Containers
Another container technology which can also run on SBCs is Linux Containers (LXC/LXD). LXC shares the host’s kernel and is lighter weight than traditional Virtual Machines. But each LXC Container is isolated via namespaces and control groups, so it appears to have its own network stack. And therefore is more flexible than Docker.
What is the difference LXC vs LXD
In this article I will treat LXC and LXD as LXC, but they are separate. LXC (or Linux Containers) existed first. Versions 1 & 2 created Virtual Machines. With version 3, LXD was added, which provides a daemon that allows easier image management, including publishing images and an API to control LXC on remote machines. LXD complements LXC by providing more features.
Qualifying the SBC OS for LXC/LXD
Unfortunately, the raspian kernel from raspberrypi.org doesn’t support namespaces.
Fortunately, there is a Ubuntu 18.04 unofficial image available for the Pi which does. This image is compressed and must be decompressed before flashed to a SD Card. Fortunately in Linux you can do this on the fly:
$ xzcat ubuntu-18.04-preinstalled-server-armhf+raspi3.img.xz | sudo dd of=/dev/sdZ bs=100M
Change sdZ to the device of your SD Card. Be careful with this command, if you give it the device of your boot drive, it will happily overwrite your boot device.
If you are using Window or a Mac, I suggest using Etcher which makes creating bootable SD Cards easy.
Make sure you follow the steps on the Ubuntu page to set an initial password for the ubuntu user. Best Practices is to setup a non-privileged user which you will use most of the time. This can be done with the adduser command. Below I have created a user craig with sudo privileges.
$ sudo adduser --ingroup sudo craig
Preparing the LXC Host (aka the Pi)
The key networking difference between Docker and LXC is that with LXC one can attach a container to any bridge on the Host. This includes a bridge on the outside interface. Via transparent bridging the container can have unfettered access to the existing IPv6 subnet, including picking up Global Unique Addresses (GUAs) without the host having to do router-like functions, such as adding routes, auto propagation of prefixes (with DHCPv6-PD), redistribution of routes, etc. Again, things which Docker doesn’t support.
Setting up an external bridge interface on the Host
Once you have the right kernel and distro, configure a bridge br0 which will in-turn have the ethernet interface as a member. This is best done from the Pi itself using a keyboard and monitor, rather than ssh-ing to a headless device. Because when you mess up, you are still connected to the Pi (believe me, it is easy to get disconnected with all interfaces down). Logically the bridge, br0 will not only be attached to the eth0 interface, but later on, the LXC Containers as well.
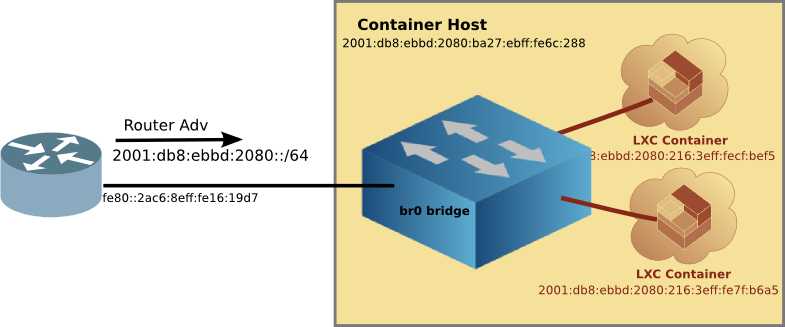
Set up the bridge
1) Install brctl the utility which controls/creates linux bridges. And install the ifupdown package which will be used later.
sudo apt-get install bridge-utils ifupdown
- Edit the
/etc/network/interfaces file to automatically set up the bridge br0 and attach the ethernet device. Add the following lines:
iface br0 inet dhcp
bridge_ports eth0
bridge_stp off
bridge_fd 0
bridge_maxwait 0
iface br0 inet6 dhcp
Because Ubuntu uses systemd we must let systemd know about the bridge, or the IPv6 default route will disappear after about 5 minutes (not good).
3) Create/Edit /etc/systemd/network/br0.network file, and add the following:
[Match]
Name=br0
[Network]
DHCP=yes
Lastly, in order to make this all work when the Pi is rebooted, we have to hack at /etc/rc.local a bit to make sure the bridge is brought up and systemd is minding it at boot up time.
4) Create/Edit /etc/rc.local and add the following, and don’t forget to make it executable.
#!/bin/bash
#
## put hacks here
# fix for br0 interface
/sbin/ifup br0
# kick networkd as well
/bin/systemctl restart systemd-networkd
echo "Bridge is up"
exit 0
Make it executable:
$ sudo chmod 754 /etc/rc.local
Finally, reboot, login and see that the Pi br0 network is up
$ ip addr
...
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master br0 state UP group default qlen 1000
link/ether b8:27:eb:6c:02:88 brd ff:ff:ff:ff:ff:ff
3: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether b8:27:eb:6c:02:88 brd ff:ff:ff:ff:ff:ff
inet 192.168.215.141/24 brd 192.168.215.255 scope global dynamic br0
valid_lft 1995525700sec preferred_lft 1995525700sec
inet6 2001:db8:ebbd:2080::9c5/128 scope global noprefixroute
valid_lft forever preferred_lft forever
inet6 2001:db8:ebbd:2080:ba27:ebff:fe6c:288/64 scope global mngtmpaddr noprefixroute
valid_lft forever preferred_lft forever
inet6 fe80::ba27:ebff:fe6c:288/64 scope link
valid_lft forever preferred_lft forever
As you can see, br0 has all the IPv4 and IPv6 addresses which is what we want. Now you can go back to headless access (via ssh) if you are like me, and the Pi is usually just sitting on a shelf (with power and network).
Installing LXC/LXD
Once setting up the br0 interface is done, we can install lxd and lxd-client. Linux Containers has been evolving of the years, and it is now (as I write this) up to version 3.0.2.
A note about versions
There is quite a bit on the internet about older versions of Linux Containers. If you see hyphenated commands like lxc-launch then stop and move to another page. Hyphenated commands are the older version 1 or 2 of Linux Containers.
A quick tour of LXC/LXD
Canonical has a nice Try It page, where you can run LXC/LXD in the comfort of your web browser without installing anything on your local machine. The Try It sets up a VM which has IPv6 access to the outside world, where you can install and configure LXC/LXD, even create Linux Containers. It is well worth the 10 minutes to run through the hands on tutorial.
Doing the install
But wait! It is already installed on this image. Although it is version 3.0.0, and the easiest way to get it to the latest version is to run:
$ sudo apt-get update
$ sudo apt-get upgrade lxd lxd-client
Add yourself to the lxd group so you won’t have to type sudo all the time.
sudo usermod -aG lxd craig
newgrp lxd
LXD Init
The LXD init script sets up LXD on the machine with a set of interactive questions. It is safe to accept all the defaults (just press return):
$ sudo lxd init
Would you like to use LXD clustering? (yes/no) [default=no]:
Do you want to configure a new storage pool? (yes/no) [default=yes]:
Name of the new storage pool [default=default]:
Name of the storage backend to use (btrfs, dir, lvm) [default=btrfs]:
Create a new BTRFS pool? (yes/no) [default=yes]:
Would you like to use an existing block device? (yes/no) [default=no]:
Size in GB of the new loop device (1GB minimum) [default=15GB]:
Would you like to connect to a MAAS server? (yes/no) [default=no]:
Would you like to create a new network bridge? (yes/no) [default=yes]:
What should the new bridge be called? [default=lxdbr0]:
What IPv4 address should be used? (CIDR subnet notation, "auto" or "none") [default=auto]:
What IPv6 address should be used? (CIDR subnet notation, "auto" or "none") [default=auto]:
Would you like LXD to be available over the network? (yes/no) [default=no]:
Would you like stale cached images to be updated automatically? (yes/no) [default=yes] no
Would you like a YAML "lxd init" preseed to be printed? (yes/no) [default=no]: no
On the Pi, LXD will take a while to think about all this, just be patient (might be 10 minutes or so).
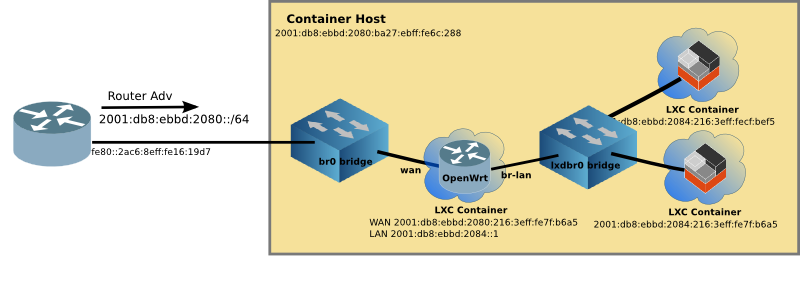
Default LXD Networking
Since we took all the defaults of lxd init it created another bridge on the system lxdbr0 which the YAML file would lead you to believe it is also bridged to the outside world, but it is not. The default config is similar to Docker, in that it creates a lxdbr0 bridge which uses NAT44 and NAT66 to connect to the outside world.
But we don’t care, because we have created a bridge br0 which is transparently bridged to the outside world. And unlike Docker, individual LXC containers can be attached to any bridge (either br0 or if you want NAT, lxdbr0)
Create a profile for the external transparent bridge (br0)
There is one more thing we have to do before running the first Linux Container, create a profile for the br0 bridge. Edit the profile to match the info below:
lxc profile create extbridge
lxc profile edit extbridge
config: {}
description: bridged networking LXD profile
devices:
eth0:
name: eth0
nictype: bridged
parent: br0
type: nic
name: extbridge
used_by:
The Linux Container network is now ready to attach containers to the br0 bridge like this:
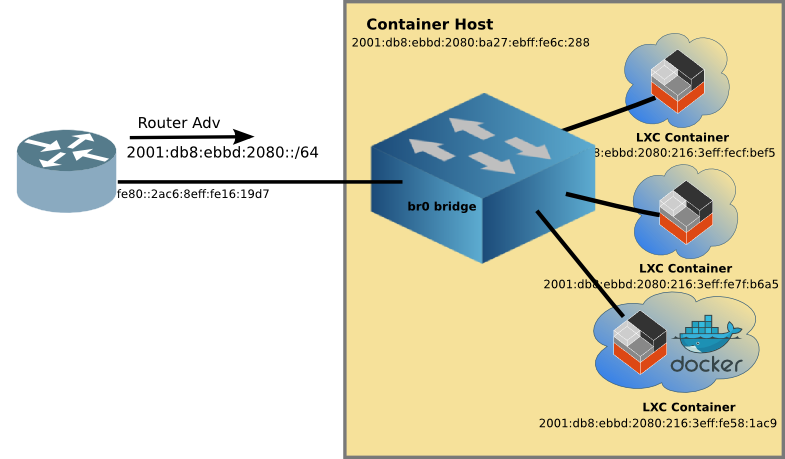
You may notice the bottom LXC container with Docker, more on this later.
Running the first Linux Container
So now it is time to have fun by running the first container. I suggest Alpine Linux because it is small, and quick to load. To create and start the container type the following:
lxc launch -p default -p extbridge images:alpine/3.8 alpine
LXD will automatically download the Alpine Linux image from the Linux Containers image server, and create a container with the name alpine. We’ll use the name alpine to manage the container going forward.
Typing lxc ls will list the running containers
$ lxc ls
+---------+---------+------------------------+----------------------------------------------+------------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+---------+---------+------------------------+----------------------------------------------+------------+-----------+
| alpine | RUNNING | 192.168.215.104 (eth0) | fd6a:c19d:b07:2080:216:3eff:fecf:bef5 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fecf:bef5 (eth0) | | |
+---------+---------+------------------------+----------------------------------------------+------------+-----------+
You will note that the container has not only a IPv4 address from my upstream DHCP server, but it also has an IPv6 GUA (and in this case, an additional IPv6 ULA, Unique Local Address).
YAML overlaying
The alpine container has a GUA because we used two -p (profile) parameters when creating it. The first is the default profile which as I mentioned earlier is set up for NAT4 and NAT6. And the second is the extbridge profile we setup as a profile. The lxc launch command pulls in the YAML info from the default profile, and then overlays the extbridge profile, effectively overwriting the parts we want so that the alpine container is attached to br0 and the outside world!
Stepping into Alpine
Of course, what good is starting a Linux Container if all you can do is start and stop it. A key difference from Docker is that Linux Containers are not read-only, but rather you can install software, configure it the way you like, and then stop the container. When you start it again, all the changes you made are still there. I’ll talk about the goodness of this a little later.
But in order to do that customization one needs to get inside the container. This is done with the following command:
$ lxc exec alpine -- /bin/sh
~ #
And now you are inside the running container as root. Here you can do anything you can do on a normal linux machine, install software, add users, start sshd, so you can ssh to it later, and so on. When you are done customizing the container type:
~ # exit
craig@pai:~$
And you are back on the LXC Host.
Advantages of customizing a container
A key advantage of customizing a container, is that you can create a template image which then can be used to create many instances of that customized application. For example, I started with alpine installed nginx and php7 and created a template image, which I called web_image. I used the following commands on the host, after installing the webserver with PHP inside the container:
$ lxc snapshot alpine snapshot_web # Make a back up of the container
$ lxc publish alpine/snapshot_web --alias web_image # publish the back up as an image
$ lxc image list # show the list of images
+--------------+--------------+--------+--------------------------------------+--------+----------+-----------------------------+
| ALIAS | FINGERPRINT | PUBLIC | DESCRIPTION | ARCH | SIZE | UPLOAD DATE |
+--------------+--------------+--------+--------------------------------------+--------+----------+-----------------------------+
| web_image | 84a4b1f466ad | no | | armv7l | 12.86MB | Dec 4, 2018 at 2:46am (UTC) |
+--------------+--------------+--------+--------------------------------------+--------+----------+-----------------------------+
| | 49b522955166 | no | Alpine 3.8 armhf (20181203_13:03) | armv7l | 2.26MB | Dec 3, 2018 at 5:11pm (UTC) |
+--------------+--------------+--------+--------------------------------------+--------+----------+-----------------------------+
Scaling up the template container
And with that webserver image, I can replicate it as many times as I have disk space and memory. I tried 10, but based on how much memory it was using, I can get to twenty on the Pi, with room for more.
$ lxc ls
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| alpine | RUNNING | 192.168.215.104 (eth0) | fd6a:c19d:b07:2080:216:3eff:fecf:bef5 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fecf:bef5 (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| w10 | RUNNING | 192.168.215.225 (eth0) | fd6a:c19d:b07:2080:216:3eff:feb2:f03d (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:feb2:f03d (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| w2 | RUNNING | 192.168.215.232 (eth0) | fd6a:c19d:b07:2080:216:3eff:fe7f:b6a5 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fe7f:b6a5 (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| w3 | RUNNING | 192.168.215.208 (eth0) | fd6a:c19d:b07:2080:216:3eff:fe63:4544 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fe63:4544 (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| w4 | RUNNING | 192.168.215.244 (eth0) | fd6a:c19d:b07:2080:216:3eff:fe99:a784 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fe99:a784 (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| w5 | RUNNING | 192.168.215.118 (eth0) | fd6a:c19d:b07:2080:216:3eff:fe31:690e (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fe31:690e (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| w6 | RUNNING | 192.168.215.200 (eth0) | fd6a:c19d:b07:2080:216:3eff:fee2:8fc7 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fee2:8fc7 (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| w7 | RUNNING | 192.168.215.105 (eth0) | fd6a:c19d:b07:2080:216:3eff:feec:baf7 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:feec:baf7 (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| w8 | RUNNING | 192.168.215.196 (eth0) | fd6a:c19d:b07:2080:216:3eff:fe90:10b2 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fe90:10b2 (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| w9 | RUNNING | 192.168.215.148 (eth0) | fd6a:c19d:b07:2080:216:3eff:fee3:e5b2 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fee3:e5b2 (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
| web | RUNNING | 192.168.215.110 (eth0) | fd6a:c19d:b07:2080:216:3eff:fe29:7f8 (eth0) | PERSISTENT | 1 |
| | | | 2001:db8:ebbd:2080:216:3eff:fe29:7f8 (eth0) | | |
+--------+---------+------------------------+----------------------------------------------+------------+-----------+
All of the webservers have their own unique IPv6 address, and all of them are running on port 80, something that can’t be done using NAT.
LXC plays well with DNS
Unlike Docker, LXC containers retain the same IPv6 address after being start and stopped. And if you are starting multiple containers, the order of starting doesn’t change the address (as Docker does).
This means that you can assign names to your LXC Containers without a lot of DNS churn. Here’s a chunk from my DNS zone file:
lxcdebian IN AAAA 2001:db8:ebbd:2080:216:3eff:feae:a30
lxcalpine IN AAAA 2001:db8:ebbd:2080:216:3eff:fe4c:4ab2
lxcweb IN AAAA 2001:db8:ebbd:2080:216:3eff:fe29:7f8
lxcw2 IN AAAA 2001:db8:ebbd:2080:216:3eff:fe7f:b6a5
lxcdocker1 IN AAAA 2001:db8:ebbd:2080:216:3eff:fe58:1ac9
DNS is your friend when using IPv6. With DNS entries, I can point my web browser to the servers running on these containers. I can even ssh in to the container, just like any host on my network.
$ ssh -X craig@lxcdebian
craig@lxcdebian's password: **********
craig@debian:~$
Key differences between LXC and Docker
Here’s a chart to show the key differences between Docker and Linux Containers.
| Docker |
LXC/LXD |
| Always Routed, and with NAT (default) |
Any Container can be routed or bridged |
| IP addressing depends on container start order |
Addressing is stable regardless of start order, and plays well with DNS |
| A read-only-like Container |
A read-write container, make it easy to customize, and templatize |
| No check on Architectures (x86, ARM) |
LXC automatically selects the correct architecture |
| Most Containers are IPv4-only |
Containers support IPv4 & IPv6 |
| Containers see Docker NAT address in logs |
Containers log real source addresses |
| Many, many containers to choose from |
By comparison, there are only a handful of pre-built containers |
A key advantage to Docker is the last one, The sheer number of Docker containers are amazing. But what if you could have the best of both worlds?
Linux Containers + Docker

No limitations |
Since LXC containers are customizable, and also since it is easy to make a template image and replicate containers based on that template, why not install Docker inside a LXC Container, and have the best of both worlds?
Actually it is quite easy to do. Start with an image that is a bit more flush than Alpine Linux, like Debian. I used Debian 10 (the next version of Debian). Create the container with:
lxc launch -p default -p extbridge images:debian/10 debian
Enable nesting feature which allows LXC to run containers inside of containers
lxc config set debian security.nesting true
lxc restart debian # restart with nesting enabled
Step into the container and customize it by installing Docker
$ lxc exec debian -- /bin/bash
# make a content directory for Docker/nginx
mkdir -p /root/nginx/www
# create some content
echo "<h2> Testing </h2>" > /root/nginx/www/index.html
# install docker and start it
apt-get install docker.io
/etc/init.d/docker start
# pull down nginx Docker Container for armhf
docker create --name=nginx -v /root/nginx:/usr/share/nginx/html:ro -p 80:80 -p 443:443 armhfbuild/nginx
# start the docker container
docker restart nginx
exit
$
And now Docker nginx is up and running inside Docker, inside a LXC Container with dual-stack predictable addressing and transparent bridging.
Make a template of the LXC + Docker Container
Follow the earlier procedure to create an image which will be used to launch customized LXC + Docker containers:
lxc snapshot debian docker_base_image
lxc publish debian/docker_base_image --alias docker_image # publish image to local:
lxc image list # see the list of images
# start a lxc/docker container called docker1
lxc launch -p default -p extbridge local:docker_image docker1
# set config to allow nesting for docker1
lxc config set docker1 security.nesting true
lxc restart docker1
Looking at the running LXC containers, it easy to spot the one running Docker (hint: look for the Docker NAT address).
lxc ls
+---------+---------+------------------------+----------------------------------------------+------------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+---------+---------+------------------------+----------------------------------------------+------------+-----------+
| alpine | RUNNING | 192.168.215.104 (eth0) | fd6a:c19d:b07:2080:216:3eff:fecf:bef5 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fecf:bef5 (eth0) | | |
+---------+---------+------------------------+----------------------------------------------+------------+-----------+
| docker1 | RUNNING | 192.168.215.220 (eth0) | fd6a:c19d:b07:2080:216:3eff:fe58:1ac9 (eth0) | PERSISTENT | 0 |
| | | 172.17.0.1 (docker0) | 2001:db8:ebbd:2080:216:3eff:fe58:1ac9 (eth0) | | |
+---------+---------+------------------------+----------------------------------------------+------------+-----------+
| w2 | RUNNING | 192.168.215.232 (eth0) | fd6a:c19d:b07:2080:216:3eff:fe7f:b6a5 (eth0) | PERSISTENT | 0 |
| | | | 2001:db8:ebbd:2080:216:3eff:fe7f:b6a5 (eth0) | | |
+---------+---------+------------------------+----------------------------------------------+------------+-----------+
| web | RUNNING | 192.168.215.110 (eth0) | fd6a:c19d:b07:2080:216:3eff:fe29:7f8 (eth0) | PERSISTENT | 1 |
| | | | 2001:db8:ebbd:2080:216:3eff:fe29:7f8 (eth0) | | |
+---------+---------+------------------------+----------------------------------------------+------------+-----------+
After getting it started, it is easy to step into the LXC container docker1 and query Docker on its container:
lxc exec docker1 -- /bin/bash
root@docker1:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
19f3cbeba6d3 linuxserver/nginx "/init" 3 hours ago Up 3 hours 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp nginx
root@docker1:~#
Running multiple LXC + Docker containers
Now that there is a template image, docker_image it is a breeze to spawn multiple LXC + Docker Containers. Don’t want them all to run nginx webservers? Easy, step into each, delete the nginx webserver and run of of the other thousands of Docker Containers.
Best of both Worlds
LXC is the best at container customization, and networking (IPv4 and IPv6). Docker is the best in the sheer volume of pre-built Docker containers (assuming you select the correct architecture, armhf for the Pi). With LXCs flexibility, it is easy to create templates to scale up multiple applications (e.g. a webserver farm running in the palm of your hand). And with LXC, it is possible to over come many of Dockers limitations opening up the world of Docker Containers to the LXC world. The best of both worlds.
originally posted with more detail on www.makikiweb.com










{kind=link}
{kind=link}